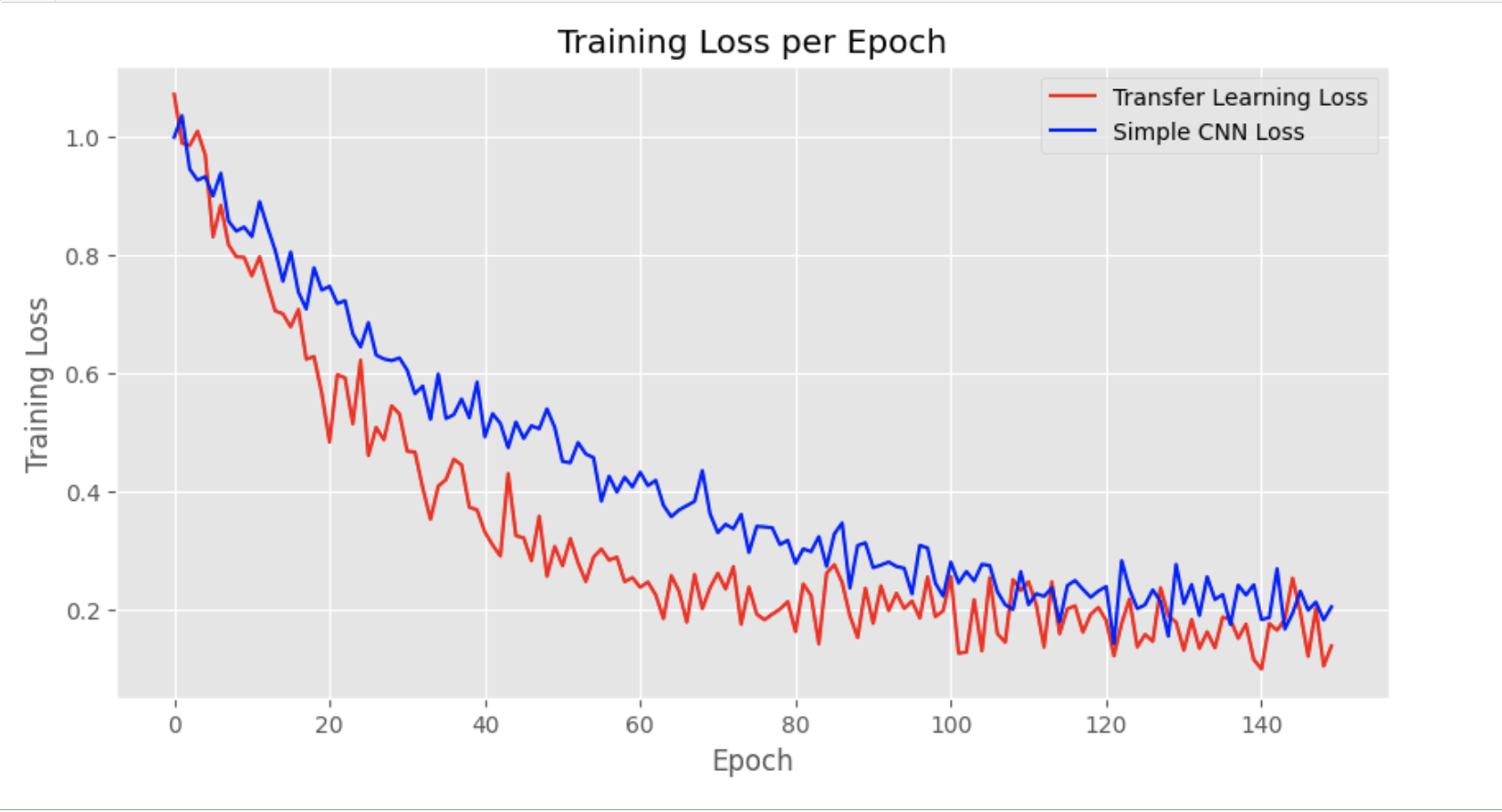
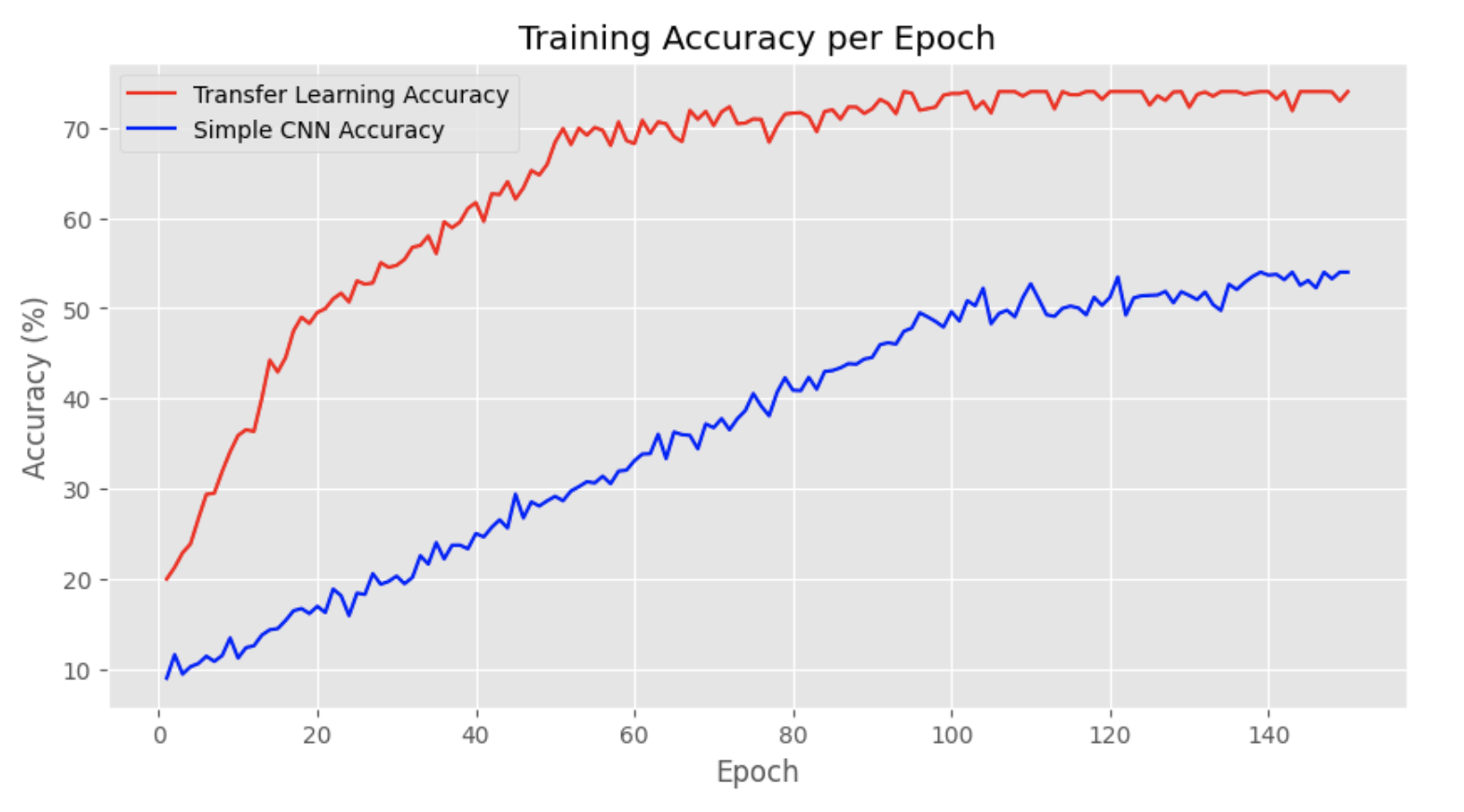
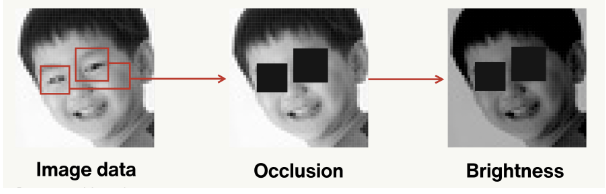
Transformers vs CNN Architectures
Understanding the differences between Transformers and CNN architectures is crucial for developing effective emotion recognition models. While CNNs are traditionally favored for image-related tasks, Vision Transformers have recently been adapted for certain computer vision tasks, offering promising results thanks to their attention mechanisms. We explore both architectures to evaluate their performance in the context of our project.
In the realm of machine learning, particularly within the scope of image processing and facial expression recognition, two primary model architectures have emerged as frontrunners: Convolutional Neural Networks (CNNs) and Vision Transformers. Each architecture brings its unique strengths to the table, shaping the way we implement emotion recognition models.
Convolutional Neural Networks (CNNs)
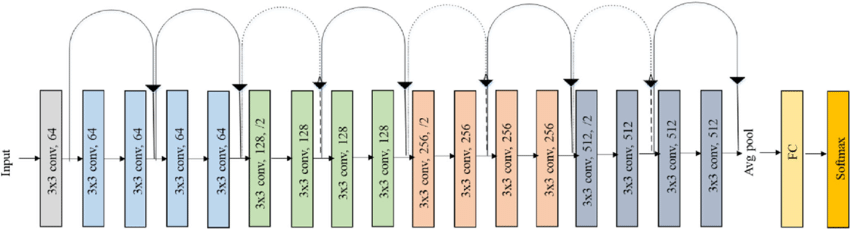
CNNs have long been the backbone of image processing tasks, renowned for their efficiency in handling spatial data. At their core, CNNs utilize convolutional layers to filter inputs for useful information, using pooling layers to reduce dimensionality and fully connected layers to make predictions. This hierarchical approach enables CNNs to capture spatial hierarchies in images, making them particularly adept at recognizing facial features and expressions. Their robustness and relative simplicity have made them a go-to choice for tasks requiring the analysis of visual data.
- Excellent at capturing spatial hierarchies and patterns within images.
- Efficient in terms of computational resources, especially for image-related tasks.
- Well-suited for tasks with a strong emphasis on texture, shape, and local features recognition.
Vision Transformers
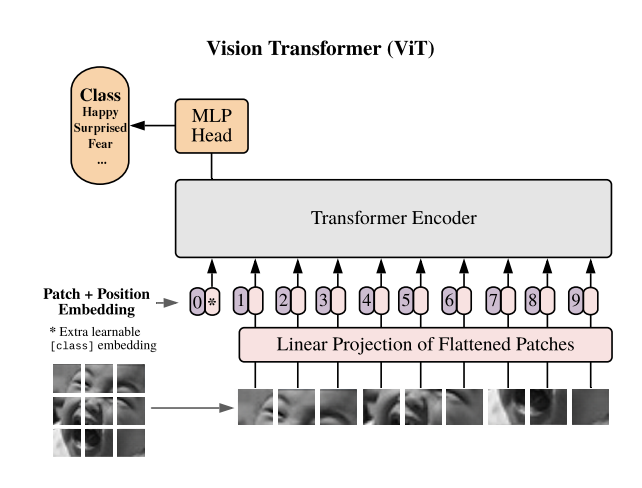
Originally designed for natural language processing (NLP) tasks, Vision Transformers have recently made significant strides in the field of image recognition. Unlike CNNs, Vision Transformers do not inherently process data in a sequential or hierarchical manner. Instead, they rely on self-attention mechanisms to weigh the importance of different parts of the input data, irrespective of their position. This allows Vision Transformers to capture global dependencies and relationships within the data, offering a new perspective on tasks traditionally dominated by CNNs.
- Capable of capturing long-range dependencies within the data, offering a broader understanding of context and relationships.
- Highly flexible and adaptable to various types of input data, beyond just images.
- Demonstrates superior performance on tasks requiring an understanding of complex patterns and global features.
Implications for Emotion Recognition
When it comes to emotion recognition, both architectures offer compelling advantages. CNNs, with their adeptness at detecting spatial patterns and features, excel at identifying the subtle nuances of facial expressions. However, their sometimes limited ability to grasp the broader context or more abstract emotional cues can be a drawback.
On the other hand, Vision Transformers, with their ability to understand global dependencies, offer a novel approach to recognizing emotions. They can potentially capture more complex emotional expressions that span across the entire face, rather than just local features. This makes them an exciting alternative for advancing emotion recognition technologies, especially in applications where understanding the nuanced expressions of children is crucial.
In our project, we aim to harness the strengths of both architectures, exploring how each can contribute to creating a more nuanced and accurate emotion recognition model. By comparing their performance across diverse datasets, including those focused exclusively on children's faces, we seek to uncover insights that will drive the future of emotional recognition technology forward.