Resnet18

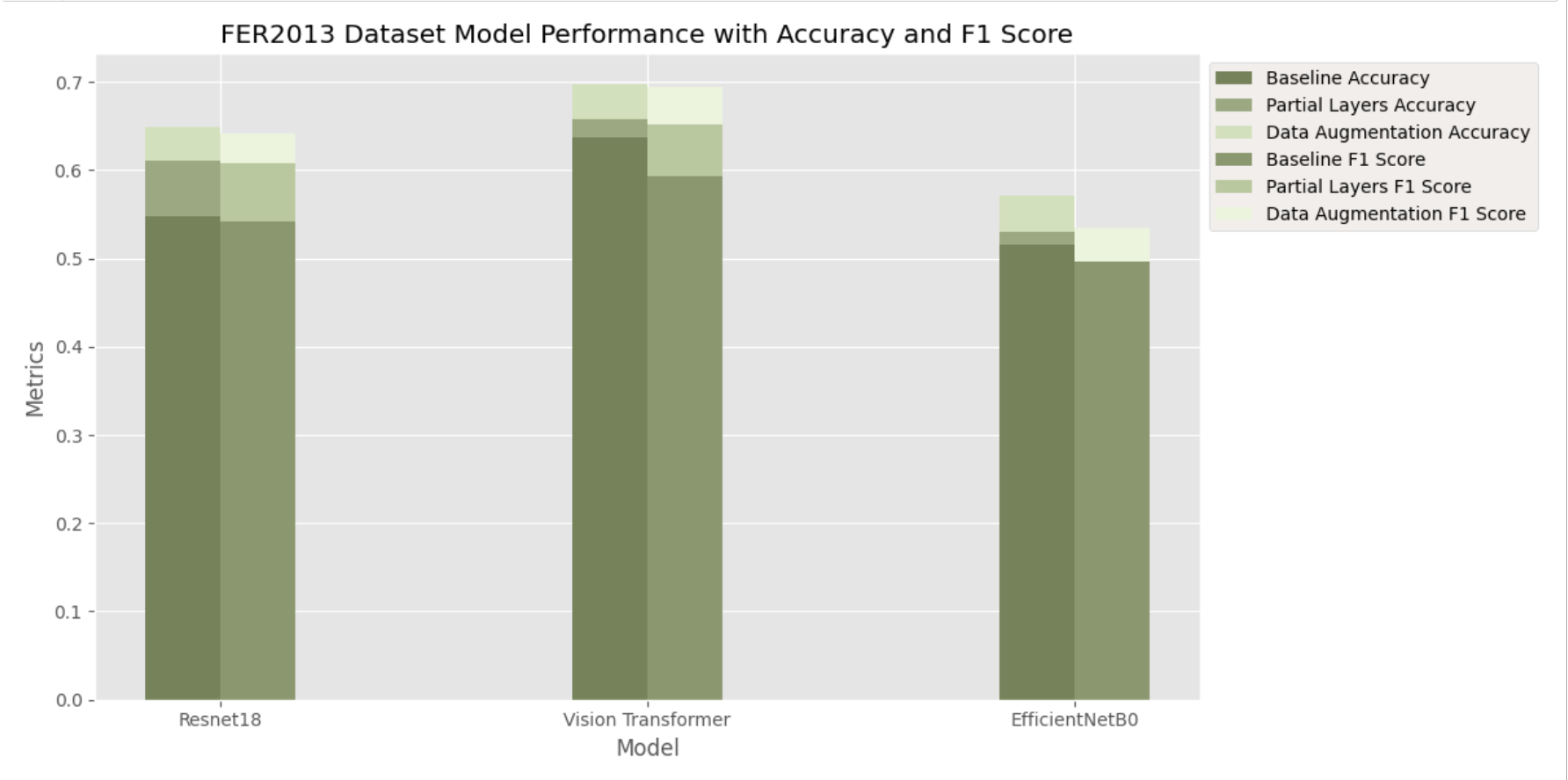
For Resnet18 on the FER2013 dataset, the baseline model achieved an accuracy and F1 score of 0.548 and 0.542 respectively. Partial layer training showed slight improvements, bring accuracy and F1 Score to 0.611 and 0.608 respectively. The usage of data augmentation yielded the most substantial improvement, with the accuracy increasing to 0.619 and the F1 Score to 0.641 on the same dataset.
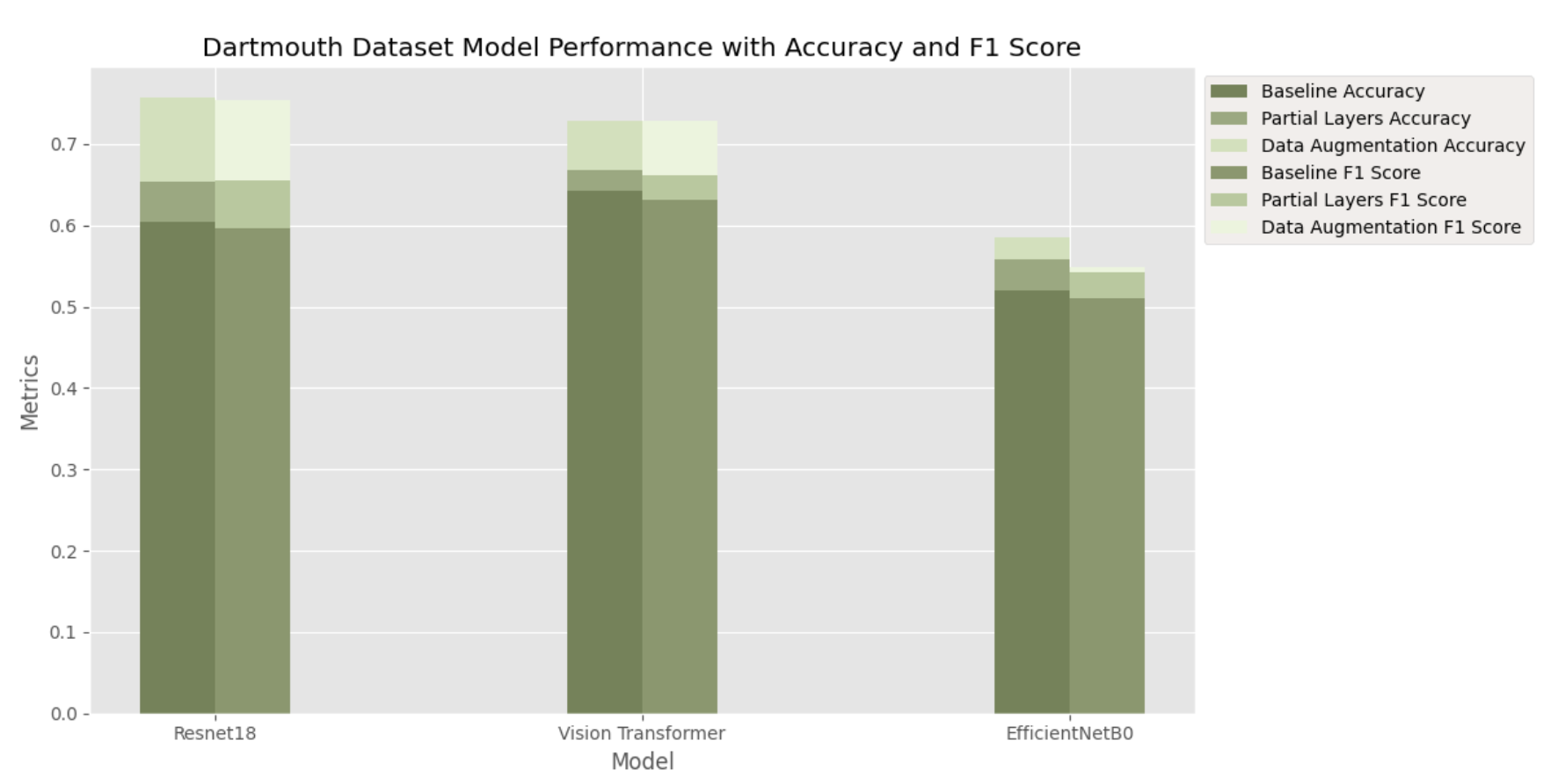
On the Dartmouth Database, baseline figures were 0.604 (accuracy) and 0.597 (F1 Score). increasing to 0.619 and the F1 Score to 0.641 on the same dataset. On the Dartmouth Database, baseline figures were 0.604 (accuracy) and 0.597 (F1 Score). Partial layer training led to slight improvements, achieving an accuracy of 0.653 and F1 Score of 0.655. Data augmentation had a significant impact, increasing accuracy to 0.757 and F1 Score to 0.754.